Biological Information Processing
Cells and computers process information quite differently. Yet computers are the basic unit of the digital world just as cells are the basic unit of life.
A National Science Foundation workshop report points out that, “ A series of discoveries over the past fifty years have illuminated the extraordinary capabilities of living cells to store and process information. We have learned that genes encoded digitally as nucleotide sequences serve as a kind of instruction manual for the chemical processes within the cell and constitute the hereditary information that is passed from parents to their offspring. Information storage and processing within the cell is more efficient by many orders of magnitude than electronic digital computation, with respect to both information density and energy consumption.” Computing professionals would do well to understand the parallels too.
All living organisms, from single cells in pond water to
humans, survive by constantly processing information about
threats and opportunities in the world around them. For example,
single-cell E-coli bacteria have a sophisticated chemical sensor
patch on one end (orange molecules in image below) that detect
several different aspects of its environment. The sensor's
output biases the cell's movement toward attractant and away
from repellent chemicals. Each individual sensor has a dynamic
range of about 102, far less than the range
encountered in their environment. However the sensor
system is cleverly
coupled such that, jointly, the sensors have a dynamic
range more than 105.
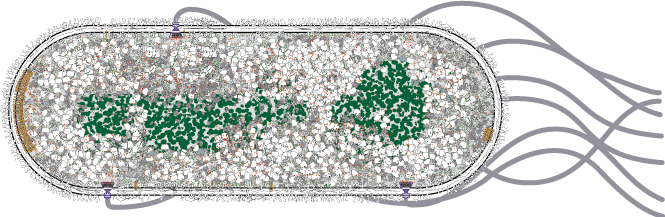
Information processing machinery within single cells involves a complex network of tens or hundreds of thousands of protein mechanisms, genes and gene-expression control pathways that dynamically adapt the cell’s function to its environment.
We cannot directly compare the information processing “power” of a cell to that of a computer. Size, power usage, robustness, and computational density clearly favor the cell whereas repeatability, precision and linear computational speed clearly favor the computer. Cells use a highly parallel architecture whereas computers use a serial architecture. Cells exploit randomness whereas computers do everything possible to suppress it. And cells apply themselves to quite different tasks than computers do. Single cell organisms are self organizing, gather their own energy, reproduce themselves, and defend themselves. All of those tasks require substantial information processing, In contrast, computers rely on their human "masters" for most of those functions. So we know, or fancy that we know, the totality of the information processing done in a computer and are still largely ignorant of the information processing done in a cell.
We may attempt to deduce something about the information
processing capacity of a cell from how much "code" it
contains. A cell's DNA plays a role roughly analogous to
program code in a computer. Although some of the DNA has been
labeled as "junk," new research casts
doubt on that notion, A human cell contains about 3.5
billion bases. Since each base is one of four possibilities (A,
T, C, G), each encodes 2 bits of information. So the human
genome contains about 7 billion bits, or roughly a Gbyte of
"code." E-coli bacteria are relatively simple by comparison;
their genome contains about 5 million bases, or about a megabyte
of "code." Other single cell organisms at least appear to be
much more complex than a human. An Amoeba (one of the most
complex single cell organisms) contains a hundred
times more DNA than a human cell. This likely is a
consequence of the fact that single cell organisms cannot specialize the way cells in
multicellular organisms do. The Amoeba must support "code" (DNA)
for all eventualities.
Cells and computers face different tasks and have quite
different capabilities. Progress has recently
been reported in computer simulations of the cellular
lifecycle processes of a very simple bacterium. Yet at this time
even the world's most powerful computer cannot simulate the
folding of a single complex protein molecule into its working
shape in anything like real-time. Nor can even the most
complex cell simulate what a mundane four function calculator
can do, especially in terms of precision and reproducibility.
Their differences not withstanding, individual computers and
single cells play similar roles in the large-scale sweep of
evolution. Just as computers are the initial unit of
computation, cells are the initial unit of life. And the
challenges of communication and collaboration between networked
computers are similar to those between cells in a multicellular
organism. (more in this
pdf presentation)
Contact: sburbeck at mindspring.com
Last revised 8/6/2013